
Robots.txt: che cos’è, a cosa serve e come utilizzarlo. Fino in fondo…
10 Apr

Robots.txt: sai davvero a cosa serve e come utilizzarlo correttamente?
In questo articolo, esploreremo in dettaglio cos’è e come funziona insieme a esempi pratici e consigli per massimizzare la visibilità del tuo sito sui motori di ricerca.
Che cos’è il file robots.txt?
Il file robots.txt è un documento in formato testuale (.txt) che consente di specificare ai crawler dei motori di ricerca quali pagine del tuo sito devono essere scansionate.
Con il file robots.txt si possono indicare agli user agent quali risorse possono essere scansionate e quali devono essere ignorate.
Che cos’è un user agent?
Un “User-agent” è un software che rappresenta l’utente in una richiesta al server. In altre parole, è un programma che comunica con un sito web o un’applicazione per conto dell’utente, inviando richieste e ricevendo risposte.
Tra gli esempi di User-agent troviamo i browser web come Chrome, Firefox e Safari.
Robots.txt: come funziona?
Ora che hai ben chiaro lo scopo principale del file robots.txt, vediamo alcuni limiti nell’utilizzo di questa preziosa risorsa.
Come riportato nella documentazione ufficiale di Google, è necessario tener conto di alcuni aspetti fondamentali:
- In primo luogo, non tutti i motori di ricerca supportano le regole del file robots.txt. Le istruzioni contenute nel file non possono imporre il comportamento del crawler, ma solo chiedere al crawler di rispettarle. Ciò significa che alcuni web crawler potrebbero non seguire le istruzioni contenute nel file.
- Ci possono essere differenze nell’interpretazione della sintassi del file a seconda del crawler. È quindi importante conoscere la sintassi più appropriata da utilizzare per i diversi web crawler per evitare confusione.
- Anche se una pagina viene bloccata dal file robots.txt, essa potrebbe comunque essere indicizzata se altri siti includono link che rimandano a quella pagina.
- Il Robots.txt è case sensitive: il file deve essere chiamato “robots.txt” (non Robots.txt, robots.TXT o altrimenti).
Altre informazioni utili:
- Il file robots.txt deve essere inserito nella directory di primo livello di un sito web, nella root del web server (esempio.com/robots.txt).
- È consigliabile specificare la posizione di eventuali sitemap relative al dominio nella parte inferiore del file robots.txt.
- Ogni sottodominio deve avere il proprio file robots.txt.
Qual è la sintassi del robots.txt ?
La sintassi del robots.txt è costituita 5 termini:
- User-agent: serve a specificare il crawler del motore di ricerca sottoposto alle direttive impostate nel robots. Se come User-agent viene specificato il simbolo “*”, le direttive vengono assegnate a tutti i crawler.
- Sitemap (opzionale): indica la posizione della sitemap.xml ai motori di ricerca.
N.B.: all’interno della sitemap vengono inserite le pagine destinate alla scansione e all’indicizzazione (comparsa nell’indice dei motori di ricerca).
Inoltre, l’URL della sitemap deve essere riportato completamente e non in modo relativo (es. Sitemap).
- Allow: indica ai crawler quali pagine possono essere scansionate.
- Disallow: indica ai crawler quali pagine non devono essere scansionate.
- Crawl-delay: direttiva utilizzata per indicare quanti secondi devono passare tra una richiesta e l’altra, prima di scansionare il contenuto della pagina.
La direttiva crawl-delay non è supportata da Googlebot. In passato, Googlebot ha utilizzato questa direttiva per limitare la frequenza di richiesta per evitare di sovraccaricare i siti web.
Tuttavia, Googlebot attualmente utilizza altri metodi per limitare la frequenza di richiesta. Quindi, la direttiva crawl-delay non è più necessaria e non è più supportata.
Altri caratteri utilizzati nella sintassi del robots.txt:
- * è un carattere jolly che rappresenta qualsiasi sequenza di caratteri.
- $ corrisponde alla fine dell’URL.
N.B.: Per ogni riga, deve esserci solo e solamente un comando disallow/allow.
Alcuni esempi di utilizzo del file robots
Esempio 1: Bloccare la scansione di un intero sito
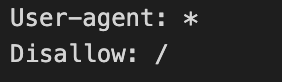
In questo esempio, non è permessa la scansione del sito a tutti gli User-agent.
Esempio 2: Permettere la scansione dell’intero sito

In questo esempio, è permessa la scansione del sito a tutti gli User-agent.
Esempio 3: Bloccare la scansione di una cartella

In questo esempio, non è permessa la scansione della cartella /giochi/ a tutti i crawler.
Esempio 4: Consentire la scansione solo per un User-agent specifico

In questo esempio, è permessa la scansione del sito solamente a Googlebot. Tutti gli altri motori di ricerca non possono avere accesso al dominio.
Esempio 5: Bloccare la scansione per una determinata pagina

In questo esempio, non è permessa la scansione della pagina /tazza-caffe.html.
Esempio 6: Bloccare la scansione per determinata tipologia di risorse
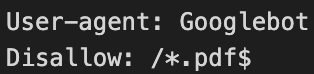
In questo esempio, il disallow impostato non permette la scansione di tutte le risorse che terminano con “.pdf”.
Robots.txt: Gli errori da evitare
Attenzione! Ci sono alcuni errori comuni che potresti commettere quando usi il file robots.txt.
Ecco i 5 più comuni:
- Lasciare il file robots vuoto
- Bloccare risorse utili
- Provare a impedire l’indicizzazione delle pagine
- Mettere in disallow una pagina contenente un tag noindex
- Bloccare pagina contenenti altri tag
1. Lasciare il file robots vuoto
Il file robots.txt, secondo le linee guida di Google, è solo necessario se vogliamo impedire la scansione del sito da parte dei crawler. Se non ci sono pagine o link che vogliamo tenere nascosti, non è necessario creare un file robots.txt.
Inoltre, i siti senza un file robots.txt, meta tag robots o intestazioni HTTP X-Robots-Tag saranno comunque sottoposti alla scansione e indicizzazione da parte dei motori di ricerca.
Pertanto, se non ci sono sezioni o URL che si desidera escludere dalla scansione, non è necessario creare un file robots.txt e soprattutto non creare una risorsa vuota.
2. Bloccare risorse utili
Il rischio più grande di utilizzare il file robots.txt in modo errato è quello di impedire la scansione di risorse e pagine importanti del sito web, che invece dovrebbero essere facilmente accessibili a Googlebot e altri crawler per il successo del progetto.
Questo può sembrare un errore banale, ma spesso si verifica che URL potenzialmente importanti vengano accidentalmente bloccati a causa di un utilizzo errato del file robots.txt.
3. Provare a impedire l’indicizzazione delle pagine
Molte volte c’è una errata comprensione dell’utilità e del funzionamento del file robots.txt e si pensa che inserire un URL in “disallow” possa evitare che la risorsa appaia nei risultati di ricerca.
Tuttavia, questo non è esatto. Utilizzare robots.txt per bloccare una pagina non impedisce a Google di indicizzarla e non serve a rimuovere la risorsa dall’indice o dai risultati di ricerca.
4. Mettere in disallow una pagina contente un tag noindex
Bloccare l’accesso ai bot su pagine con meta tag noindex rende inefficace il tag stesso, poiché i bot non possono identificarlo. Ciò può portare alla visualizzazione di pagine con meta tag noindex nei risultati di ricerca.
Per evitare che una pagina appaia nei risultati di ricerca, è necessario implementare il meta tag noindex e consentire l’accesso ai bot su quella pagina.
5. Bloccare pagine contenenti altri tag
Come abbiamo già menzionato, bloccare un URL impedisce ai crawler di leggere il contenuto delle pagine e anche di interpretare i comandi impostati, tra cui quelli importanti menzionati in precedenza.
Per permettere a Googlebot e simili di leggere e considerare correttamente gli status code o i meta tag degli URL, è necessario evitare di bloccare tali risorse nel file robots.txt.
Quali sono le differenze tra Robots.txt, x-robot tag e meta robots
Ecco in breve le differenze tra Robots.txt, x-robot tag e meta robots:
- Il file robots.txt ti permette di influenzare il comportamento e l’attività di scansione del crawler di fronte a determinate risorse.
- Intestazione HTTP x-robot tag può determinare in che modo i contenuti vengono visualizzati nei risultati di ricerca (o per assicurarti che non vengano mostrati). La direttiva può essere dichiarata attraverso l’intestazione HTTP.
- Anche il meta tag robots può determinare in che modo i contenuti vengono visualizzati nei risultati di ricerca (o per assicurarti che non vengano mostrati). La direttiva viene inserita nell’HTML della singola pagina.
Come testare il file robots.txt
Per testare il file robots.txt di un sito web puoi utilizzare la Google Search Console.
Google Search Console (GSC) è uno strumento gratuito offerto da Google che consente ai proprietari di siti web di monitorare e migliorare la loro presenza sui motori di ricerca.
GSC include anche una funzione di verifica del file robots.txt, dove è possibile verificare se il file è stato configurato correttamente e se ci sono eventuali problemi con esso.
Per accedere e utilizzare lo strumento, segui questi semplici step:
- Accedi al seguente link
- Selezione la tua proprietà
- Inserisci l’URL della pagina da testare nella casella in fondo alla pagina
- Seleziona lo User-Agent desiderato con il dropdown vicino alla casella di inserimento
- Cliccare il bottone “TEST”
Se viene restituito “ALLOWED”, allora vuol dire che la scansione è permessa per la pagina testata. Invece, se viene restituito “BLOCKED”, vuol dire che la scansione non è permessa per la pagina testata.
Come alternativa a Google Search Console, è disponibile lo strumento di test del file robots.txt di Merkle.
Studio Cappello Agenzia SEO
Potrebbero interessarti:
 I Nuovi Miti Nella SEO
I Nuovi Miti Nella SEO Seo Roadmap Ecommerce: Per Aumentare Traffico E Revenue
Seo Roadmap Ecommerce: Per Aumentare Traffico E Revenue Web Crawling: Non È Solo “Roba Da SEO”
Web Crawling: Non È Solo “Roba Da SEO” SEO Entity E Google SGE (Search Generative Experience): Cosa Sta Cambiando?
SEO Entity E Google SGE (Search Generative Experience): Cosa Sta Cambiando? Santo Graal dell’Ecommerce: 91 check per ottimizzare le conversioni
Santo Graal dell’Ecommerce: 91 check per ottimizzare le conversioni Amazon Advertising genera rendimenti più elevati rispetto a Facebook ADS o Google ADS?
Amazon Advertising genera rendimenti più elevati rispetto a Facebook ADS o Google ADS? Le Migliori Estensioni SEO Magento
Le Migliori Estensioni SEO Magento Google Remarketing Tips: ti trovo, ti inseguo, ti converto…
Google Remarketing Tips: ti trovo, ti inseguo, ti converto…





